Claude Opus 4.8 wurde veröffentlicht. Für nachhaltige Eigenständigkeit bei langfristigen Aufgaben und ein aufrichtigeres Verhalten.

Inhaltsverzeichnis
Hallo. Am 29. Mai 2026 hat Anthropic das neue Claude-Modell „Claude Opus 4.8" für die Allgemeinheit veröffentlicht.
Opus 4.7 ist erst etwa anderthalb Monate alt, und schon kommt der Nachfolger.
Ehrlich gesagt war die Dynamik in der KI-Coding-Welt zuletzt enorm von OpenAIs Codex geprägt – die Entwicklung neigte sich deutlich in Richtung Codex. Selbst Leute, die bisher immer gesagt hatten „Für Coding ist Claude Code die beste Wahl", wechselten nach und nach zu Codex als ihrer Hauptlösung. In den sozialen Medien gab es sogar Stimmen, die sagten: „Claude braucht man nicht mehr." Ich persönlich mag jedoch Anthropics Philosophie und Herangehensweise, und die Entwicklungserfahrung mit Claude Code ist mir schlicht deutlich lieber – also blieb ich ohne Zögern bei Claude Code.
Vor diesem Hintergrund war Opus 4.8 für mich persönlich ein lang ersehntes Upgrade. Ich bin erstaunt über das anhaltende Entwicklungstempo und spüre gleichzeitig eine gewisse Zuversicht, dass hier nochmal ein Gang höhergeschaltet wurde.
Was ich beim Lesen der Ankündigung als Erstes wahrgenommen habe: Der Fokus hat sich von „beeindruckenden Zahlen" hin zu „leichterer Delegierbarkeit von Aufgaben" verschoben. Auch der offizielle Einführungstext nennt nicht zuerst hohe Benchmark-Werte, sondern drei Punkte: „schärferes Urteilsvermögen (sharper judgment)", „mehr Ehrlichkeit über den eigenen Fortschritt (more honesty about its own progress)" und „die Fähigkeit, länger selbstständig zu arbeiten (the ability to work independently for longer)".
In diesem Artikel fasse ich auf Basis der offiziellen Ankündigung zusammen, was Opus 4.8 auszeichnet und wie sich das auf die tägliche Arbeit auswirkt. Der Preis bleibt gegenüber Opus 4.7 unverändert, und über die API ist das Modell unter der Modell-ID claude-opus-4-8 verfügbar.
Die drei Säulen von Opus 4.8
Anthropic nennt drei Achsen der Weiterentwicklung:
- Schärferes Urteilsvermögen – Verbesserte Entscheidungsfindung in schwierigen Situationen
- Ehrlichkeit über den eigenen Fortschritt – Präzise Rückmeldung darüber, was erledigt wurde und was nicht
- Längere selbstständige Arbeit – Aufgaben werden auch in langen Sessions ohne häufige Eingriffe zu Ende geführt
Im Folgenden betrachten wir diese Punkte sowohl aus Benchmark- als auch aus praktischer Perspektive.
Leistung anhand von Benchmarks
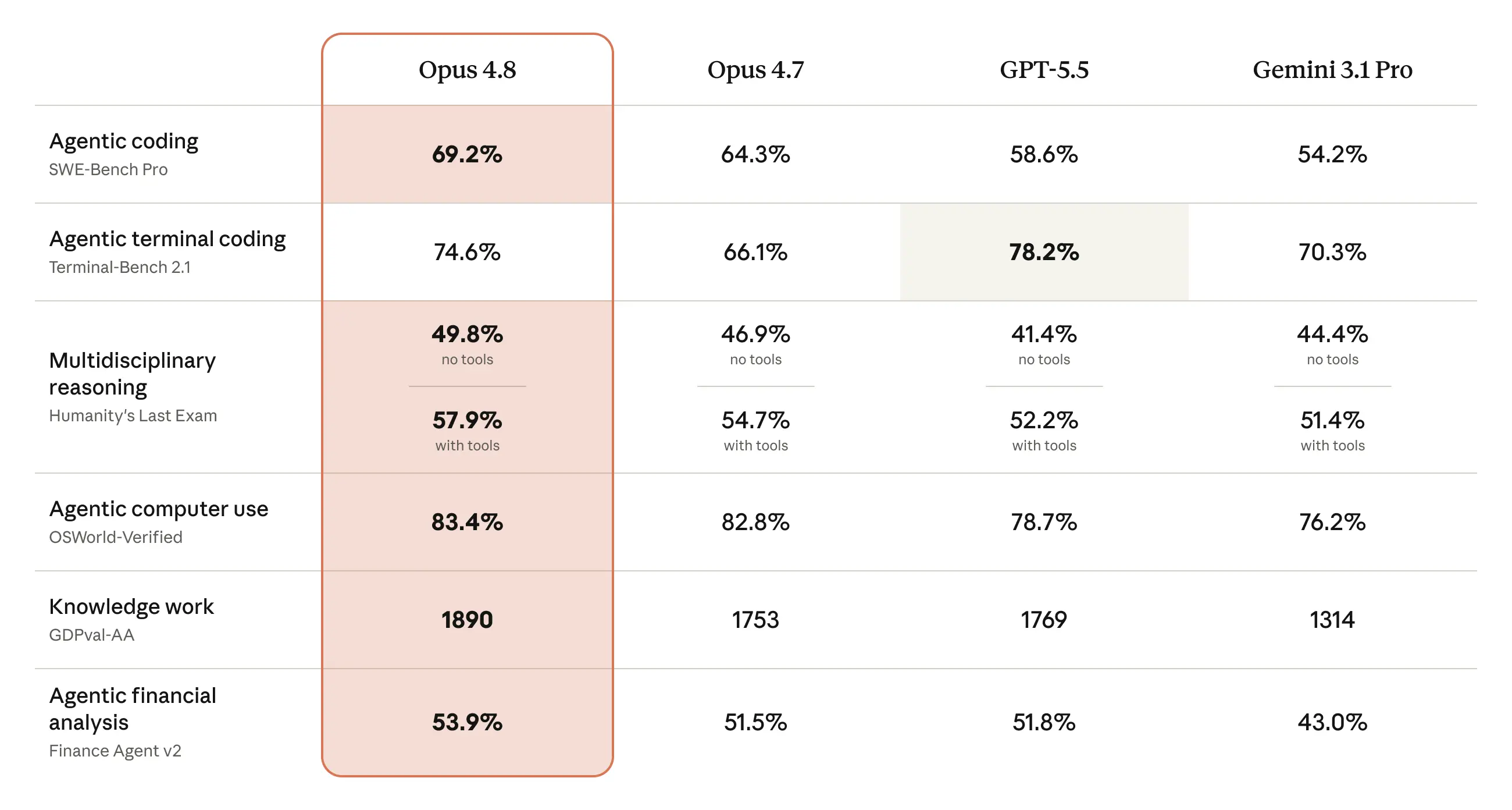
Zunächst ein Blick auf die wichtigsten Benchmarks, die offiziell veröffentlicht wurden. Es gibt Vergleichszahlen mit Opus 4.7 sowie mit GPT-5.5 und Gemini 3.1 Pro von anderen Anbietern.
 (Quelle:Introducing Claude Opus 4.8 \ Anthropic)
(Quelle:Introducing Claude Opus 4.8 \ Anthropic)
Auf den ersten Blick zeigt sich, dass Opus 4.8 in vielen Bereichen – Coding (SWE-Bench Pro: 69,2 %), Reasoning (Humanity's Last Exam), Computerbedienung, Wissensarbeit (GDPval-AA) und Finanzanalyse – eine Stufe über Opus 4.7 liegt.
Der Fairness halber sei erwähnt: Beim Terminal-Bench 2.1 (agentenbasiertes Coding im Terminal) liegt GPT-5.5 mit 78,2 % vorne und übertrifft damit Opus 4.8 mit 74,6 %. Opus 4.8 ist also nicht in jeder Kategorie führend. Dennoch ist der Fortschritt beim SWE-Bench Pro von 64,3 % auf 69,2 % sowie der deutliche Vorsprung beim GDPval-AA (1753 → 1890) bemerkenswert – das deutet darauf hin, dass die Verbesserungen vor allem bei praxisnahen Aufgaben spürbar sind.
Benchmarks sind natürlich nur ein Ausschnitt, aber die ehrliche Einschätzung lautet: „Gegenüber der Vorgängergeneration solide und vor allem in praxisrelevanten Bereichen gewachsen."
Selbstständigkeit – Längere Aufgaben delegieren
Was mich persönlich bei diesem Update am meisten interessiert, ist die verbesserte „Selbstständigkeit".
Offiziell wird das Verhalten in Claude Code so beschrieben: „makes calls like an experienced engineer without needing constant check-ins" – also: Entscheidungen treffen wie ein erfahrener Ingenieur, ohne ständige Rückfragen. Auch in langen Sessions bleibt das Modell auf Kurs und arbeitet Aufgaben im Repository vollständig ab. Das ermöglicht es, das Hinzufügen eines Features oder das Zusammenfassen einer Bugfix-Arbeit komplett zu delegieren und sich selbst der nächsten Aufgabe zu widmen.
Lassen Sie mich das etwas ausführlicher erklären. Bisheriges KI-Coding erforderte zwangsläufig den Kreislauf „Anweisung geben → Ausgabe prüfen → Kurs korrigieren". Je länger die Aufgabe, desto mehr summierte sich dieser Prüfaufwand – man war letztlich ständig dabei. Opus 4.8 ist darauf ausgerichtet, diese Hin-und-her-Schleifen zu reduzieren.
Konkret ändert sich die Arbeitsweise zum Beispiel so:
- „Füge diese Funktion hinzu und sorge dafür, dass die zugehörigen Tests durchlaufen" – und in der Zwischenzeit selbst Design-Reviews oder andere Aufgaben erledigen
- Einen Repository-weiten Bug-Sweep delegieren und die Ergebnisse gesammelt prüfen
- Ein größeres Refactoring laufen lassen, während man selbst die Spezifikationen ausarbeitet
Kurz gesagt: KI entwickelt sich von einem „Werkzeug, dem man Schritt für Schritt Anweisungen gibt" hin zu einem „Partner, dem man größere Aufgabenpakete anvertrauen kann". Wie weit man tatsächlich delegieren kann, hängt von der Art der Aufgabe und dem eigenen Prompt ab – aber als Designphilosophie ist diese Ausrichtung für jemanden, der täglich mit Claude Code arbeitet, eine sehr willkommene Entwicklung.
Ehrlichkeit – Weniger „scheinbar erledigte" Aufgaben
Von den drei Säulen ist die Verbesserung der „Ehrlichkeit (honesty)" diejenige, die ich persönlich für die praktische Arbeit am wirkungsvollsten halte. Auch offiziell heißt es: „Eine der auffälligsten Verbesserungen in Opus 4.8 ist seine Ehrlichkeit (honesty)."
Konkret wurden folgende Verhaltensweisen gestärkt:
- Unsicherheiten bei der eigenen Arbeit werden proaktiver kommuniziert (flag uncertainties)
- Unbelegte Behauptungen werden seltener aufgestellt (less likely to make unsupported claims)
Und die Zahl, die mich am meisten beeindruckt hat:
Opus 4.8 is around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked.
Frei übersetzt: „Die Wahrscheinlichkeit, dass Opus 4.8 Fehler im selbst geschriebenen Code stillschweigend durchgehen lässt, ist etwa viermal geringer als bei der Vorgängergeneration."
Das klingt unscheinbar, ist in der Praxis aber erheblich. Das Frustrierendste beim Delegieren an KI ist, wenn sie selbstbewusst „Fertig!" meldet, obwohl es noch Lücken gibt. Das kostet Nacharbeit und erhöht den eigenen Prüfaufwand. Da Opus 4.8 häufiger von sich aus meldet „Hier bin ich unsicher" oder „Das sollte noch geprüft werden", lässt sich der Review gezielter angehen.
„Verbesserte Selbstständigkeit" und „verbesserte Ehrlichkeit" wirken zusammen. Lange selbstständig arbeiten zu können nützt wenig, wenn das Modell dabei unehrlich über seinen Fortschritt ist. Erst die Kombination aus „kann lange laufen" und „ist ehrlich über den eigenen Fortschritt" macht es möglich, Aufgaben wirklich vertrauensvoll zu delegieren.
Als ich noch Angestellter war, sagte mein Vorgesetzter: „Wenn alles reibungslos läuft, musst du nicht ständig Bericht erstatten. Aber wenn irgendetwas schiefläuft oder ein Problem auftaucht, melde dich sofort." Das gilt für Menschen wie für KI gleichermaßen.
Fast Mode deutlich günstiger geworden
Auch in Bezug auf Geschwindigkeit und Kosten gibt es eine wichtige Neuerung. Opus 4.8 bietet einen Fast Mode, der zudem deutlich günstiger ist als zuvor.
Der Fast Mode ist eine Hochgeschwindigkeitskonfiguration, die dasselbe Opus 4.8 mit etwa 2,5-facher Geschwindigkeit betreibt. Offiziell heißt es „2.5× the speed" für die Ausgabe-Token. Es handelt sich nicht um ein anderes Modell, sondern um eine schnellere Betriebsweise von Opus 4.8 selbst.
Und der Preis ist im Vergleich zum Fast Mode früherer Modelle dreimal günstiger geworden. Im Überblick:
| Nutzungsform | Eingabe (pro 1M Tokens) | Ausgabe (pro 1M Tokens) |
|---|---|---|
| Standard (unverändert gegenüber Opus 4.7) | $5 | $25 |
| Fast Mode | $10 | $50 |
Der Standardpreis von $5 / $25 bleibt gegenüber Opus 4.7 unverändert. Der Fast Mode kostet das Doppelte mit $10 / $50, aber da dies laut Ankündigung „ein Drittel des Preises des früheren Fast Mode" ist, sinkt die Hürde für geschwindigkeitskritische Szenarien erheblich.
In Claude Code lässt sich der Fast Mode mit dem Befehl /fast aktivieren (für Entwickler, bei denen „extra usage" aktiviert ist). Wer ihn über die API nutzen möchte, kann sich an seinen Account Manager wenden oder sich über das Fast Mode-Anmeldeformular auf die Warteliste setzen. Derzeit ist er sowohl in Claude Code als auch auf der Claude Platform als eingeschränkte Research Preview verfügbar.
Für die Arbeit eignet sich der Fast Mode besonders gut für iterative Aufgaben. Bei häufigen kleinen Korrekturen oder interaktivem Verfeinern kommt die schnellere Antwortzeit direkt dem Arbeitsfluss zugute. Vielleicht ergibt sich eine natürliche Aufteilung: Schwierige Probleme, bei denen man gründliches Nachdenken wünscht, im Standardmodus – temporeichere Aufgaben im Fast Mode. Oder wenn ein kritischer Bug in der Produktionsumgebung sofort behoben werden muss.
Dynamic Workflows (Research Preview)
Als neue Funktion auf der Claude Code-Seite ist auch Dynamic Workflows als Research Preview erschienen.
Dieses System ist für die anspruchsvollsten Aufgaben gedacht: Claude erstellt zunächst einen Plan, lässt Hunderte von Subagenten parallel laufen, verifiziert die Ergebnisse selbst und liefert sie dann zurück. Als Beispiel nennt die offizielle Ankündigung „Migrationen über Hunderte von Dateien" – Migrationen im Umfang von Hunderttausenden von Codezeilen sollen von Anfang bis zum Merge in einem Durchgang bewältigt werden können.
Zur Erklärung: Ein Subagent ist ein Hilfsagent, der vom Hauptprozess abzweigt und einen bestimmten Teilauftrag übernimmt. Indem eine große Anzahl davon parallel betrieben wird, können umfangreiche Änderungen mit vielen Dateien aufgeteilt und gleichzeitig bearbeitet werden.
Zu Dynamic Workflows plane ich einen separaten, ausführlicheren Artikel. Es ist eine Funktion, die man im Hinterkopf behalten sollte – als Kandidat für Aufgaben wie große Refactorings oder Massenmigrationen, die bisher tagelange manuelle Arbeit erforderten.
Verbesserungen bei Sicherheit und Alignment
Neben der Leistung werden auch Verbesserungen im Bereich Sicherheit (Alignment) berichtet.
„Alignment" bezeichnet hier das Konzept, das Verhalten einer KI mit menschlichen Absichten und Werten in Einklang zu bringen. Es ist eine von der reinen Leistungsfähigkeit unabhängige Dimension – vereinfacht gesagt geht es darum, ob die KI ihre Fähigkeiten sicher und integer einsetzt.
Laut offizieller Bewertung ist die Häufigkeit von Fehlverhalten (misaligned behavior) bei Opus 4.8 – etwa Täuschung (deception) oder Kooperation bei Missbrauch (cooperation with misuse) – gegenüber Opus 4.7 deutlich gesunken. Das Niveau soll sich dem von Claude Mythos Preview angenähert haben, dem Modell, das Anthropic als am besten ausgerichtet betrachtet.
Claude Mythos Preview ist das Modell, das Anthropic als „best-aligned model" einstuft. Dass Opus 4.8 nun ein vergleichbares Niveau erreicht hat, ist auch im Hinblick auf das vertrauensvolle Delegieren von Aufgaben ein nicht zu unterschätzender Punkt.
Vergleichstabelle: Opus 4.7 vs. Opus 4.8
Hier sind die wichtigsten Unterschiede zusammengefasst:
| Merkmal | Opus 4.7 | Opus 4.8 |
|---|---|---|
| Entwicklungsachsen | Coding-Stärkung, Instruktionsbefolgung, Vision | Urteilsvermögen, Ehrlichkeit, Langzeit-Selbstständigkeit |
| SWE-Bench Pro | 64,3 % | 69,2 % |
| Humanity's Last Exam (mit Tools) | 54,7 % | 57,9 % |
| GDPval-AA (Wissensarbeit) | 1753 | 1890 |
| Übersehen von Code-Fehlern | – | Auf ca. ein Viertel der Vorgängergeneration reduziert |
| Alignment | Generell gut (best-aligned: Mythos Preview) | Misaligned behavior stark gesunken, auf Niveau von Mythos Preview |
| Preis (Standard, Eingabe/Ausgabe) | $5 / $25 pro 1M Tokens | $5 / $25 pro 1M Tokens (unverändert) |
Was bedeutet das für Nutzer?
Lassen Sie mich das Bisherige aus der Perspektive „Wie wirkt sich das auf meine Arbeit aus?" neu ordnen.
1. Weniger Rückfragen, mehr Zeit für sich selbst
Durch die verbesserte Selbstständigkeit lassen sich „in sich geschlossene Aufgaben" wie das Hinzufügen von Features oder Bug-Sweeps delegieren, während man selbst andere Dinge erledigt. Weniger Zeit, die man der KI gewidmet verbringt, bedeutet mehr Konzentration auf das, was Menschen tun sollten: Design und Spezifikationsarbeit.
2. Einfacheres Review, weniger Nacharbeit
Die Verbesserung „viermal seltener werden Code-Fehler stillschweigend übergangen" wirkt sich direkt auf Qualität und Effizienz des Reviews aus. Wenn die KI vorab meldet „Hier bin ich unsicher", lässt sich der Review gezielter durchführen. Das erschöpfendste Muster – „Es hieß, es sei fertig, aber es gab doch Lücken" – tritt seltener auf.
3. Wahl zwischen Geschwindigkeit und Kosten
Da der Fast Mode dreimal günstiger geworden ist, wird die Aufteilung „Fast Mode für Situationen, in denen Geschwindigkeit gefragt ist; Standardmodus für schwierige Probleme, die gründliches Nachdenken erfordern" realistisch. Der Stress bei iterativen Aufgaben, die schnell abgearbeitet werden sollen, nimmt ab.
4. Mehr Optionen für umfangreiche Aufgaben
Durch Dynamic Workflows rücken Aufgaben wie Migrationen im Umfang von Hunderten von Dateien und Hunderttausenden von Codezeilen in den Bereich des Delegierbaren – Aufgaben, bei denen man bisher gezögert hätte. Auch ein Einsatz über das Wochenende ist denkbar.
5. Leistungssteigerung ohne Preiserhöhung
Der Standardpreis bleibt gegenüber Opus 4.7 unverändert. Die Leistungsverbesserungen ohne zusätzliche Kosten zu erhalten, ist schlicht erfreulich.
Insgesamt empfinde ich Opus 4.8 als ein Update, das weniger auf „beeindruckende Einzelleistungen" als auf „vertrauensvolles, langfristiges Delegieren" ausgerichtet ist. Je mehr man KI als täglichen Entwicklungspartner nutzt, desto stärker dürfte dieser Unterschied spürbar werden.
In Claude Code ausprobieren
In einer Umgebung, in der Opus 4.8 verfügbar ist, lässt es sich über den Befehl /model in der neuesten Version von Claude Code auswählen. Falls es noch nicht angezeigt wird, bitte nach einem Update neu starten.
claude update
Um den Fast Mode auszuprobieren, führen Sie in Claude Code /fast aus (Extra Usage muss aktiviert sein).
Verfügbarkeit und Standardverhalten können je nach Plan, Anbieter und Administratoreinstellungen variieren. Wer Claude Code noch über Homebrew oder npm verwendet, sollte diesen Moment nutzen, um auf die native Installation umzusteigen – damit greifen automatische Updates, und neue Funktionen lassen sich reibungsloser übernehmen. Die genaue Vorgehensweise ist in diesem Artikel zusammengefasst: „Wie ich von der Homebrew-Installation von Claude Code zur nativen Installation gewechselt bin und es angenehmer wurde."
Zusammenfassung
Die wichtigsten Neuerungen von Claude Opus 4.8 im Überblick:
- Verbesserungen entlang drei Achsen: schärferes Urteilsvermögen, Ehrlichkeit und Langzeit-Selbstständigkeit
- Auch in Benchmarks Verbesserungen in praxisnahen Bereichen: SWE-Bench Pro 69,2 %, GDPval-AA 1890
- Wahrscheinlichkeit, Fehler im selbst geschriebenen Code zu übersehen, auf ca. ein Viertel der Vorgängergeneration reduziert
- Fast Mode verfügbar: 2,5-fache Geschwindigkeit, dreimal günstiger als zuvor ($10 / $50)
- Dynamic Workflows (Research Preview) ermöglichen das Delegieren großer Migrationen
- Alignment verbessert: Misaligned behavior auf das Niveau von Mythos Preview gesunken
- Standardpreis unverändert gegenüber Opus 4.7 ($5 / $25)
Dass innerhalb von nur anderthalb Monaten seit Opus 4.7 so viel erreicht wurde, ist beeindruckend – aber das Thema dieses Updates ist weniger „Zurschaustellung von Intelligenz" als vielmehr „leichtere Delegierbarkeit". Ein Schritt in Richtung: lange laufen können, ehrlich über den eigenen Fortschritt sein, vertrauensvoll Aufgaben anvertrauen können.
Wer es noch nicht ausprobiert hat: Es ist über Claude Code, claude.ai oder die API zugänglich. Wählen Sie mit /model Opus 4.8 aus und erleben Sie den Unterschied in Selbstständigkeit und Ehrlichkeit in Ihrem eigenen Workflow.