Claude Opus 4.8 Released: Towards Long-Term Autonomy and More Sincere Behavior

Table of Contents
Hello. On May 29, 2026, Anthropic officially released its new Claude model, "Claude Opus 4.8."
It has only been about a month and a half since Opus 4.7 appeared, but the next one is already here.
To be honest, in the recent AI coding scene, OpenAI's Codex has had incredible momentum, and the trend was clearly leaning toward Codex. Even people who used to say "Claude Code is the best for coding" were switching to Codex one after another. Some on social media even went as far as saying, "We don't need Claude anymore." But well, I like Anthropic's direction and philosophy, and I overwhelmingly prefer the development experience of Claude Code, so I stuck with Claude Code without a second thought.
Given that timing, this Opus 4.8 upgrade was something I've been personally waiting for. While I'm surprised by the usual speed of evolution, I feel a sense of reliability seeing them shift into a higher gear here.
Reading this announcement, my first impression was that the focus has shifted from "impactful numbers" to "ease of delegating work." Even the official introduction lists three points before mentioning high benchmarks: "sharper judgment," "more honesty about its own progress," and "the ability to work independently for longer."
In this article, based on the official announcement, I will organize the features of Opus 4.8 and how they affect daily work. The price remains the same as Opus 4.7, and it is available via API with the model ID claude-opus-4-8.
The Three Pillars of Opus 4.8
Anthropic has highlighted three main axes of evolution:
- Sharper judgment - Improved decision-making in difficult situations.
- More honesty about its own progress - Accurately reporting what it has and hasn't done.
- The ability to work independently for longer - Completing work through long sessions without needing constant intervention.
Let's look at these from both benchmark and practical perspectives.
Performance in Benchmarks
First, here is a comparison of the major benchmarks released officially. The figures show Opus 4.8 alongside Opus 4.7, as well as competitors like GPT-5.5 and Gemini 3.1 Pro.
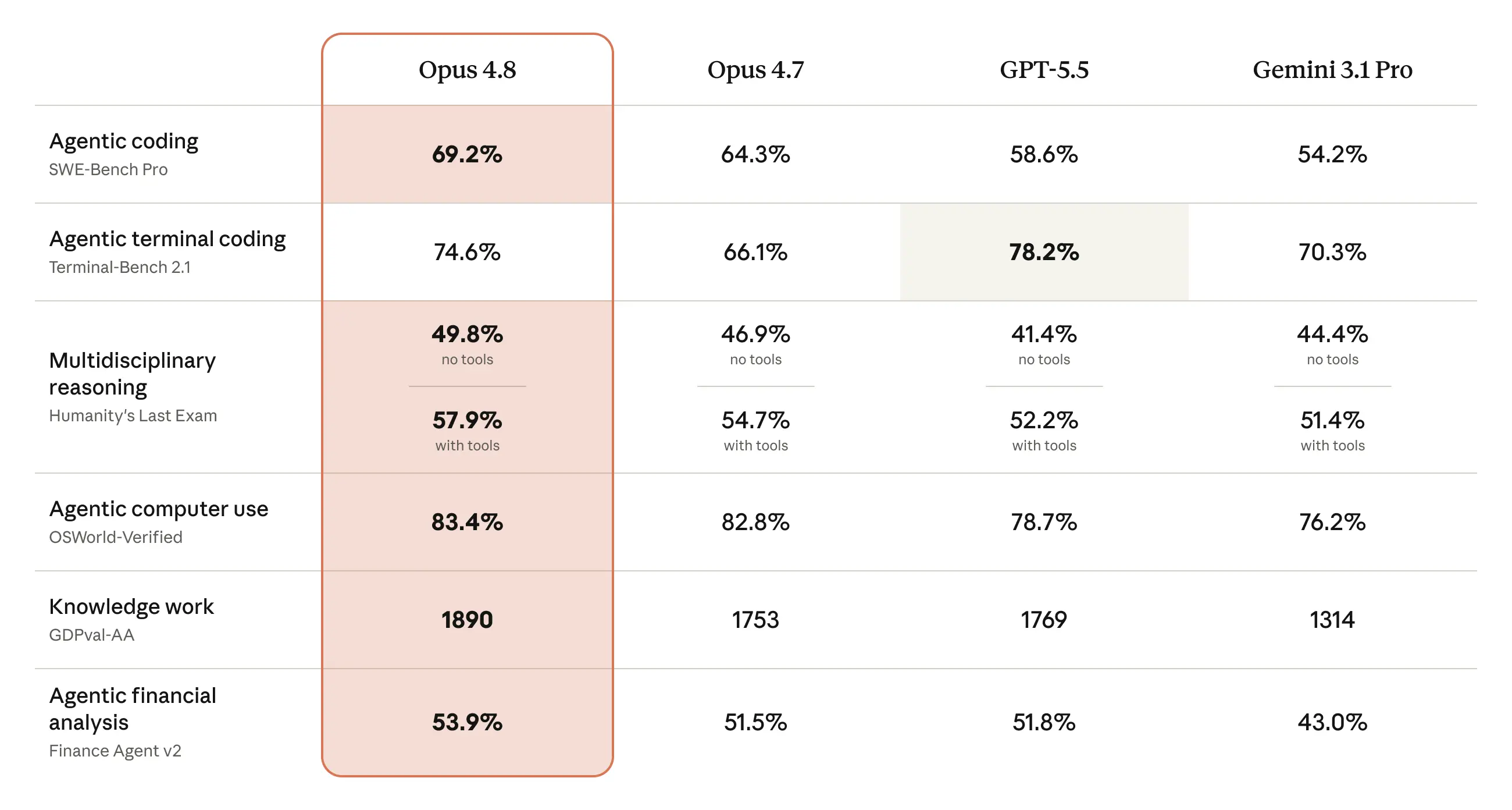 (Source: Introducing Claude Opus 4.8 \ Anthropic)
(Source: Introducing Claude Opus 4.8 \ Anthropic)
Looking at the numbers, Opus 4.8 shows a step up from Opus 4.7 in many areas: coding (69.2% on SWE-Bench Pro), reasoning (Humanity's Last Exam), computer use, knowledge work (GDPval-AA), and financial analysis.
To be fair, GPT-5.5 leads in Terminal-Bench 2.1 (agentic coding in a terminal) with 78.2%, which is higher than Opus 4.8's 74.6%. It isn't number one in every single category. However, seeing the growth from 64.3% to 69.2% in SWE-Bench Pro and the lead in GDPval-AA (measuring knowledge work) with a score of 1890 vs 1753, it's clear that the improvements are effectively targeting practical, real-world tasks.
While benchmarks are only one side of the story, the straightforward takeaway is that the model is growing steadily from the previous generation, specifically along axes relevant to professional work.
Autonomy - Capable of Longer Assignments
Personally, the improvement I'm most excited about is this "autonomy."
Regarding its behavior in Claude Code, the official description says it "makes calls like an experienced engineer without needing constant check-ins." It doesn't derail even during long sessions and follows through on tasks within a repository until the end. This allows for a workflow where you can hand over an entire feature addition or bug fix and move on to your next task while it works.
Let's break this down. Until now, AI coding inevitably required a back-and-forth of "instruct → check output → correct course." For long tasks, this verification cost would pile up, often resulting in the user having to stay glued to the screen. Opus 4.8 is designed to reduce this back-and-forth.
In terms of workflow, this changes things in scenarios like:
- Asking it to "add this feature and make sure all related tests pass," while you focus on design reviews or other tasks.
- Assigning it a repository-wide "bug sweep" and then reviewing the compiled results later.
- Running a large refactor in the background while you proceed with specification planning.
In short, the direction is moving the AI from a "tool you must instruct step-by-step" to a "partner you can entrust with a chunk of work." How much you can actually leave to it depends on the nature of the task and your prompts, but as a design philosophy, this is a very welcome change for someone who uses Claude Code daily.
Honesty - Fewer "I thought I did it" moments
Among the three pillars, I feel "honesty" is the improvement that will have the most impact on practical work. Anthropic even states, "One of the most notable improvements in Opus 4.8 is its honesty."
Specifically, the following behaviors have been strengthened:
- More actively flagging uncertainties in its own work.
- Less likely to make unsupported claims.
And this was the most impressive statistic for me:
Opus 4.8 is around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked.
In other words, Opus 4.8 is about four times less likely to overlook a flaw in the code it wrote without saying anything.
This might seem subtle, but it's a huge deal in practice. The most frustrating thing when relying on AI is when it returns a confident "Done!" but actually has holes in the implementation. This leads to rework and increases the burden of verification. Since Opus 4.8 is more likely to report "this part is questionable" or "you should check this," it becomes much easier to know where to focus your review.
"Increased autonomy" and "increased honesty" work together as a set. Even if it can run for a long time, you can't trust it if it lies about being finished. The combination of being able to work longer while being honest about its progress is what brings it closer to being a reliable partner in a professional setting.
When I was a salaried employee, my boss used to say, "You don't need to report every detail when things are going smoothly. But the moment you're in trouble or a problem occurs, report it immediately." Human society and AI are the same in that regard.
Fast Mode is Significantly Cheaper
There are also big moves in terms of speed and cost. Opus 4.8 supports Fast mode, and it is significantly cheaper than before.
Fast mode is a high-speed configuration that runs the same Opus 4.8 at approximately 2.5x the speed. To use the official phrasing, output tokens are returned at "2.5× the speed." This isn't a switch to a different model, but rather a configuration to run Opus 4.8 itself faster.
Furthermore, the price is 3 times cheaper compared to Fast mode on previous models. Here is the breakdown:
| Usage Type | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| Standard (Same as Opus 4.7) | $5 | $25 |
| Fast mode | $10 | $50 |
The standard rates of $5 / $25 remain unchanged from Opus 4.7. Fast mode is double that at $10 / $50, but since this is "one-third the price of the previous Fast mode," the barrier to using it when speed is a priority has dropped significantly.
In Claude Code, you can switch using the /fast command (for developers with extra usage enabled). If you want to use it via API, you need to contact your account manager or join the waitlist via the Fast mode application form. Currently, it is positioned as a limited research preview for both Claude Code and the Claude Platform.
In a professional context, this seems ideal for high-iteration tasks. When doing small fixes repeatedly or refining things through dialogue, the speed of response directly translates to a more comfortable experience. You might use standard mode for difficult problems that require deep thought, and Fast mode when you want to keep the momentum going. It would also be useful for urgent fixes, like a critical bug in production.
Dynamic Workflows (Research Preview)
As a new feature on the Claude Code side, dynamic workflows have also arrived in research preview.
This is a mechanism for the most difficult tasks where Claude first creates a plan, runs hundreds of subagents in parallel, and then verifies the results itself before reporting back. The official announcement uses a "migration involving hundreds of files" as an example, stating it can handle migrations across codebases of hundreds of thousands of lines from start to merge.
To clarify, subagents are auxiliary agents that branch off from the main task to handle specific subtasks. The idea is that by running a large number of these in parallel, massive changes involving many files can be handled efficiently.
I plan to cover dynamic workflows in more detail in a separate article. It's a feature worth remembering as a candidate for tasks that used to take humans days, such as large-scale refactoring or bulk migrations.
Improvements in Safety and Alignment
Beyond performance, improvements in safety (alignment) have also been reported.
"Alignment" refers to the concept of making an AI's behavior consistent with human intentions and values. It's helpful to think of it as a separate axis from raw capability—evaluating whether that capability can be used safely and honestly.
According to official evaluations, Opus 4.8 has a significantly lower rate of "misaligned behavior" than Opus 4.7—for example, deception or cooperation with misuse. The explanation is that its level of alignment has reached a point comparable to Claude Mythos Preview, which the company considers its best-aligned model.
Claude Mythos Preview is a high-end model that Anthropic positions as its "best-aligned model." The fact that Opus 4.8 has reached that same level is a point that shouldn't be overlooked when it comes to entrusting it with professional work.
Comparison Table: Opus 4.7 vs. Opus 4.8
Here is a summary of the main differences.
| Item | Opus 4.7 | Opus 4.8 |
|---|---|---|
| Focus of Evolution | Coding enhancement, Instruction following, Vision improvement | Judgment, Honesty, Long-term autonomy |
| SWE-Bench Pro | 64.3% | 69.2% |
| Humanity's Last Exam (with tools) | 54.7% | 57.9% |
| GDPval-AA (Knowledge work) | 1753 | 1890 |
| Overlooking code flaws | - | Reduced to approx. 1/4 of the previous generation |
| Alignment | Generally good (Mythos Preview is best) | Misaligned behavior significantly reduced; same level as Mythos Preview |
| Pricing (Standard - Input/Output) | $5 / $25 per 1M tokens | $5 / $25 per 1M tokens (Unchanged) |
Why This Matters to Users
Let's re-examine these points from the perspective of "how it affects your work."
1. Less back-and-forth means more free time for you
With increased autonomy, you can hand over "chunks of work" like feature additions or bug sweeps and proceed with other things in the meantime. As the time you spend glued to the AI decreases, you can focus more on parts that require human input, such as design and specification review.
2. Reviews become easier and rework decreases
The improvement where "the probability of silently overlooking code flaws is reduced to 1/4" directly impacts the quality and efficiency of reviews. If the AI flags "this part is suspicious" beforehand, it becomes easier to know where to check. Reducing the most draining pattern—where it says it's done but actually has holes—is a major win.
3. Choose the balance between speed and cost
With Fast mode becoming three times cheaper, it's now realistic to switch between "Fast mode when speed is needed" and "Standard mode for difficult problems." This reduces the stress of iterative tasks where you want to move quickly.
4. More options for delegating large-scale tasks
With dynamic workflows, there's now a candidate for tasks that were previously daunting, such as migrations involving hundreds of files and hundreds of thousands of lines. You could even consider running these over the weekend.
5. Performance gains without a price hike
Standard usage rates remain the same as Opus 4.7. Receiving performance improvements at no additional cost is purely a good thing.
Overall, I feel Opus 4.8 is an update geared toward "reliable delegation" rather than just "flashy, one-off cleverness." The more you use AI as a partner in daily development, the more you will feel the difference.
Trying it in Claude Code
If you are in an environment where Opus 4.8 is available, you can select it via the /model command in the latest version of Claude Code. If you don't see it yet, try updating and restarting.
claude update
If you want to try Fast mode, you can switch by running /fast in Claude Code (requires extra usage to be enabled).
Note that availability and default behavior vary depending on your plan, provider, and admin settings. For those still using Claude Code via Homebrew or npm, switching to a native installation at this time will ensure automatic updates and smoother access to new features. Detailed steps are summarized in Switching Claude Code from Homebrew to Native Installation Made It Much Better (Japanese article).
Summary
The evolution points of Claude Opus 4.8 can be summarized as follows:
- Improvements across three pillars: sharper judgment, honesty, and long-term autonomy.
- Benchmark boosts in practical areas: SWE-Bench Pro (69.2%) and GDPval-AA (1890).
- Probability of overlooking flaws in its own code reduced to about 1/4 of the previous generation.
- Introduction of Fast mode: 2.5x speed and 3x cheaper than before ($10 / $50).
- Dynamic workflows (research preview) for delegating large-scale migrations.
- Improved alignment, with misaligned behavior dropping to the level of Mythos Preview.
- Standard usage pricing remains unchanged from Opus 4.7 ($5 / $25).
It's surprising to see this much progress only a month and a half after Opus 4.7, but the theme this time felt less like "boasting about intelligence" and more about "ease of delegation." It's a step toward an AI that can run longer, is honest about its progress, and can be trusted with more responsibility.
If you haven't tried it yet, you can do so via Claude Code, claude.ai, or the API. Select Opus 4.8 with /model and experience the difference in autonomy and honesty within your own workflow.